{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




|
The Web server is the brain of your presentation, the mission control center. It's the mechanism without which your presentation would just be a pile of HTML pages on your disk, unnoticed and unpublished.
Hyperbole aside, your Web server is basically just a program you set up and install like any other program. Besides being the part of your Web presentation that actually allows your pages to be published, the Web server does provide an enormous amount of extra value to your presentation in the use of CGI scripts, clickable images, and (as you'll learn about in the next chapter) protecting files from unauthorized users.
In this chapter, I'll describe some of the fun things you can do with your server to make your presentations easier for you to manage and for your readers to access, including the following major topics:
| Note |
As in the previous chapters, I've focused on HTTPD servers for UNIX in this chapter. Much of the information applies to servers in general, however, so a lot of this chapter might be useful to you if you are running a server on another platform. |
The NCSA includes are a capability in the NCSA HTTPD server and other servers based on it (for example, Apache and WebSite) that enable you to write parsed HTML files. Parsed HTML files have special commands embedded in them, and when someone requests that file, the Web server executes those commands and inserts the results in the HTML file. NCSA server includes enable you to do the following:
Server includes allow a great deal of flexibility for including information in your HTML files, but because every parsed HTML file must be processed by the server, parsed HTML files are slower to be loaded and create a larger load on the server itself. Also, in the case of server includes that run CGI scripts, they could open your server up to security problems.
This section describes each of the different kinds of include statements you can do, as well as how to set up your server and your files to handle them.
| Note |
This section, and most of the rest of this chapter, assumes you have your own server and that you can configure it the way you want it to behave. If you're using someone else's server, they may or may not have many of these features. Ask your Webmaster or server adminstrator for more information about what your server supports. |
In order to use server includes, your server must support them, and you will usually have to explicitly configure your server to run them.
In servers based on NCSA, there are two modifications you need to make to your configuration files:
| Note |
Your server may support server includes but have a different method of turning them on. See the documentation that comes with your server. |
Server includes can be enabled for an entire server or for individual directories. Access to server includes can also be denied for certain directories.
To enable server includes for all the files in your Web tree, edit the access.conf file in your configuration directory (usually called conf).
| Note |
The global access control file might have a different name or location specified in your httpd.conf file. |
In your access.conf file, add the following line to globally enable server includes:
Options Includes
Instead of globally enabling server includes, you can also enable includes only for specific directories on your server. For example, to allow server-side includes only for the directory /home/www/includes, add the following lines to access.conf:
<Directory /home/www/includes>
Options Includes
</Directory>
| Note |
You can also enable includes for an individual directory by using an access control file in that directory, usually called .htaccess. You'll learn about access control in the next chapter. |
For either global or per-directory access, you can enable includes for everything, except includes that execute scripts, by including this line instead:
Options IncludesNoExec
Now edit your srm.conf file, which is also usually contained in that configuration directory. Here you'll add a special server type to indicate the extension of the parsed HTML files, the files that have server includes in them. Usually those files will have a .shtml extension. To allow the server to handle files with that extension, add the following line:
AddType text/x-server-parsed-html .shtml
Or, you can turn on parsing for all HTML files on your server by adding this line instead:
AddType text/x-server-parsed-html .html
If you do this, note that all the HTML files on your server will be parsed, which will be slower than just sending them.
After editing your configuration files, restart your server, and you're all set!
Now that you've set up your server to handle includes, you can put include statements in your HTML files and have them parsed when someone accesses your file.
Server include statements are indicated using HTML comments (so that they will be ignored if the server isn't doing server includes). They have a very specific form that looks like this:
<!--command arg1="value1"-->
In the include statement, the command is the include command that will be executed, such as include, exec, or echo (you'll learn about these as we go along). Each command takes one or more arguments, which can then have values surrounded by quotes. You can put these include statements anywhere in your HTML file, and when that file is parsed, the comment and the commands will be replaced by the value that the statement returns: the contents of a file, the values of a variable, or the output of a script, for example.
For the server to know that it needs to parse your file for include statements, you have to give that file the special extension that you set up in the configuration file, usually .shtml. If you set up your server to parse all files, you won't need to give it a special extension.
One form of server include does not include anything itself; instead, it configures the format for other include statements. The #config command configures all the include statements that come after it in the file. #config has three possible arguments:
| errmsg | If an error occurs while trying to parse the include statements, this option indicates the error message that is printed to the HTML file and in the error log. |
| timefmt | This argument sets the format of the time and date, as used by several of the include options. The default is a date in this format:
Wednesday, 26-Apr-95 21:04:46 PDT |
| sizefmt | This argument sets the format of the value produced by the include options that give the size of a file. Possible values are "bytes" for the full byte value, or "abbrev" for a rounded-off number in kilobytes or megabytes. The default is "abbrev". |
Here are some examples of using the #config command:
<!--#config errmsg="An error occurred"-->
<!--#config timefmt="%m/%d/%y"-->
<!--#config sizefmt="bytes"-->
<!--#config sizefmt="abbrev"-->
Table 27.1 shows a sampling of the date and time formats you can
use for the timefmt argument.
The full listing is available in the strftime(3)
man page on UNIX systems.
| Results | |
| The full date and time, like this: Wed Apr 26 15:23:29 1995 | |
| The abbreviated date, like this: 04/26/95 | |
| The abbreviated time (in a 24-hour clock), like this: 15:26:05 | |
| The abbreviated month name (Jan, Feb, Mar) | |
| The full month name (January, February) | |
| The month as a number (1 to 12) | |
| The abbreviated weekday name (Mon, Tue, Thu) | |
| The full weekday name (Monday, Tuesday) | |
| The day of the month as a number (1 to 31) | |
| The abbreviated year (95, 96) | |
| The full year (1995, 1996) | |
| The current hour, in a 24-hour clock | |
| The current hour, in a 12-hour clock | |
| The current minute (0 to 60) | |
| The current second (0 to 60) | |
| a.m. or p.m. | |
| The current time zone (EST, PST, GMT) |
You can use server-side includes simply to include the contents of one file in another HTML file. To do this, use the #include command with either the file or virtual arguments:
<!--#include file="signature.html"-->
<!--#include virtual="/~foozle/header.html"-->
Use the file argument to specify the file to be included as a relative path from the current file. In that first example, the signature.html file would be located in the same directory as the current file. You can also indicate files in subdirectories of the current directory (for example, file="signatures/mysig.html"), but you can't access files in directories higher than the current one (that is, you cannot use ".." in the file argument).
Use virtual to indicate the full pathname of the file you want to include as it appears in the URL, not the full file-system pathname of the file. So, if the URL to the file you wanted to include was http://myhost.com/~myhomedir/file.html, the pathname you would include in the first argument would be "/~myhomedir/file.html" (you need that leading slash).
The file that you include can be a plain HTML file, or it can be a parsed HTML file, allowing you to nest different files within files, commands within files within files, or any combination you would like to create. However, the files you include can't be CGI scripts; use the exec command to do that, which you'll learn about later on in this chapter in "Including Output from Commands and CGI Scripts."
Server includes also give you a way to print the variables of several predefined variables, including the name or modification date of the current file or the current date.
To print the value of a variable, use the #echo command with the var argument and the name of the variable, like this:
<!--#echo var="LAST_MODIFIED"-->
<P> Today's date is <!--#echo var="DATE_LOCAL"--></P>
Table 27.2 shows variables that are useful for the #echo
command.
| Variable | Value |
| DOCUMENT_NAME | The filename of the current file |
| DOCUMENT_URI | The pathname to this document as it appears in the URL |
| DATE_LOCAL | The current date in the local time zone |
| DATE_GMT | The current date in Greenwich Mean Time |
| LAST_MODIFIED | The last modification data of the current document |
If you've followed the advice I gave in previous chapters, each of your Web pages includes a signature or address block at the bottom with your name, some contact information, and so on. But every time you decide to change the signature, you have to edit all your files and change the signature in every single one. It's bothersome, to say the least.
Including a signature file on each page is an excellent use of server includes because it enables you to keep the signature file separate from your HTML pages and include it on-the-fly when someone requests one of those pages. If you want to change the signature, you only have to edit the one file.
In this exercise, we'll create an HTML document that automatically includes the signature file. And, we'll create the signature file so that it contains the current date. Figure 27.1 shows the final result after we're done (except that the current date will be different each time).
Figure 27.1 : The signature as included in the current document.
First, let's create the signature file itself. Here, we'll include all the typical signature information (copyright, contact information, and so on), preceded by a rule line, like this:
<HR>
<ADDRESS>
This page Copyright © 1995 Susan Agave susan@cactus.com
</ADDRESS>
| Note |
Because this file is intended to be included in another file, you don't have to include all the common HTML structuring tags as you usually would, such as <HTML> and <HEAD>. |
Just for kicks, let's include the current date in the signature file as well. To do this, we'll add the include statement to print out the DATE_LOCAL variable, plus a nice label:
<BR>Today's date is <!--#echo var="DATE_LOCAL"-->
Now save the file as signature.shtml, install it on your Web server, and you can test it by just accessing it from your favorite browser. Figure 27.2 shows what we've got so far. Well, it works, but that date format is kind of ugly. It would be nicer if it had just the month, day, and year.
Figure 27.2 : The signature file.
To change the date format, use a #config include statement with the timefmt directive %x (which, according to Table 27.1, will print out the date in the format we want). The include statement with #config can go anywhere in the file before the date include, but we'll put it up at the top. The final signature.shtml file looks like this:
<!--#config timefmt="%x"-->
<HR>
<ADDRESS>
This page Copyright © 1995 Susan Agave susan@cactus.com
<BR>Today's date is <!--#echo var="DATE_LOCAL"-->
</ADDRESS>
Now let's move on to the file that will include the signature file. Let's just use a short version of the all-too-familiar Susan's Cactus Gardens home page. The HTML code for the page is as follows:
<HTML>
<HEAD>
<TITLE>Susan's Cactus Gardens: A Catalog</TITLE>
</HEAD>
<BODY>
<P><IMG SRC="cactus.gif" ALIGN=MIDDLE ALT="">
<STRONG>Susan's Cactus Gardens</STRONG></P>
<H1>Choosing and Ordering Plants</H1>
<UL>
<LI><B><A HREF="browse.html">Browse Our Catalog</A></B>
<LI><B><A HREF="order.html">How To Order</A></B>
<LI><B><A HREF="form.html">Order Form</A></B>
</UL>
</BODY>
</HTML>
Include a line at the end (after the list, before the </BODY> tag for the signature file) as a server include statement:
<!--#include file="signature.shtml"-->
Save this file as a parsed HTML file (say, cactus.shtml). When you enter its URL into a browser, the signature file is also parsed, and the final file with the date is stuck in the right place in the Cactus file.
Unlike the #include command, the #fsize and #flastmod commands enable you to insert the size and last modified date for a specified file. The arguments to both of these commands are the same as for the #include command:
| file | Indicates the name of a file relative to the current file |
| virtual | Indicates the full pathname to the file as it appears in the URL |
The format of the #fsize command is dependent on the value of sizefmt, if it has been previously defined in a #config include. For example, if a file called signature.html is 223 bytes long, the following line returns the value This file is 1K bytes long:
<BR>This file is <!--#fsize file="signature.html"--> bytes long
The following lines return the value This file is 223 bytes long:
<!--#config sizefmt="bytes"-->
<BR>This file is <!--#fsize file="signature.html"--> bytes long
For #flastmod, the output of the date is dependent on the value of timefmt, as also defined in #config. For example, these lines return This file was last modified on 2/3/95 (assuming, of course, that the signature.html file was indeed last modified on that date):
<!--#config timefmt="%x"-->
<BR>This file was last modified on
<!--#flastmod file="signature.html"-->.
Finally, if the includes in the previous sections didn't do what you want, you can write one as a command or a CGI script that does. Then, you can call it from a server include so the output of that script is what gets printed in the final HTML file. These kinds of includes are called exec includes, after the #exec command.
There are two arguments that the #exec include can take:
| cmd | The name of a command that can be executed by the Bourne shell (/bin/sh). It can be either a system command such as grep or echo, or a shell script you've written (in which case you need to specify its entire pathname to the cmd argument). |
| cgi | The pathname to a CGI script, as it appears in the URL. The CGI script you run in an exec include is just like any other CGI script. It must return a Content-type as its first line, and it can use any of the CGI variables that were described in Chapter 19, "Beginning Cgi Scripts." It can also use any of the variables that you could use in the #echo section as well, such as DATE_LOCAL and DOCUMENT_NAME. |
Here are some examples of using CGI-based server includes to run programs on the server side:
<!--#exec cmd="last | grep lemay | head"-->
<!--#exec cmd="/usr/local/bin/printinfo"-->
<!--#exec cgi="/cgi-bin/pinglaura"-->
One complication with calling CGI scripts within server include statements is that you can't pass path information or queries as part of the include itself, so you can't do this:
<!--#exec cgi="/cgi-bin/test.cgi/path/to/the/file"-->
How do you pass arguments to a CGI script using an include statement? You pass them in the URL to the .shtml file itself that contains the include statement.
What? Say that again.
Yes, it's really confusing and doesn't seem to make any sense. Here's an example to make it (somewhat) clearer. Suppose you have a CGI script called docolor that takes two arguments-an X and a Y coordinate-and returns a color. (This is a theoretical example; I don't know why it would return a color. I just made it up.)
You also have a file called color.shtml, which has an #exec include statement to call the CGI script with hardcoded arguments (say, 45 and 64). In other words, you want to do the following in that color.shtml file:
<P>Your color is <!--exec cgi="/cgi-bin/docolor?45,64"-->.</P>
You can't do that. If you call the CGI script directly from your browser, you can do that. If you call it from a link in an HTML file, you can do that. But you can't do it in an include statement; you'll get an error.
However, what you can do is include those arguments in the URL for the file color.shtml. Suppose you have a third file that has a link to color.shtml, like this:
<A HREF="color.shtml">See the Color</A>
To call the script with arguments, put the arguments in that link, like this:
<A HREF="color.shtml?45,62">See the Color</A>
Then, in color.shtml, just call the CGI script in the include statement with no arguments:
<P>Your color is <!--exec cgi="/cgi-bin/docolor"-->.</P>
The CGI script gets the arguments in the normal way (on the command line or through the QUERY_STRING environment variable) and can return a value based on those arguments.
A number of programs exist for doing access counts. Some of them even create little odometer images for you. In this example, we'll create a very simple access counter that does the job.
To do access counts, you're going to need three things:
First, look at the counts file. This is the number of times your file has been accessed. You can either initialize this file at 1 or look through your server logs for an actual count. Then, create the file (here we'll create one called home.count with the number 0 in it):
echo 0 > home.count
You'll also have to make the count file world-writable so that the server can write to it (remember, the server runs as the user nobody). You can make the home.count file world writable using the chmod command:
chmod a+w home.count
Second, you'll need a script that prints out the number and updates the file. Although you could do this as a CGI script (and many of the common access counters out there will do that), we'll make this easy and just use an ordinary shell script. Here's the code for that script:
#!/bin/sh
countfile=/home/www/lemay/home.count
nums=`cat $countfile`
nums=`expr $nums + 1`
echo $nums > /tmp/countfile.$$
cp /tmp/countfile.$$ $countfile
rm /tmp/countfile.$$
echo $nums
The only thing you should change in this script is the second line. The countfile variable should be set to the full pathname of the file you just created for the count. Here, it's in my Web directory in the file home.count.
Save that script in the same directory as your counts file and the HTML file you're counting accesses to. You don't need to put this one in a cgi-bin directory. Also, you'll want to make it executable and run it a few times to make sure it is indeed updating the counts file. I've called this script homecounter.
Now all that's left is to create the page that includes the access
count. Here I've used a
no-frills home page for an individual named John (who isn't very
creative):
<HTML><HEAD>
<TITLE>John's Home Page</TITLE>
</HEAD></BODY>
<H1>John's Home Page</H1>
<P>Hi, I'm John. You're the
<!--#exec cmd="./homecounter"-->th person to access this file.
</BODY></HTML>
The second-to-last line is the important one. That line executes the homecounter command from the current directory (which is why it's ./homecounter and not just homecounter), which updates the counter file and inserts the number it returned into the HTML for the file itself. So, if you save the file as a .shtml file and bring it up in your browser, you'll get something like what you see in Figure 27.3.
Figure 27.3 : John's home page with access counters.
That's it! You have a simple access counter you can create on your own. Of course, most of the access counters available on the Web are slightly more sophisticated and allow you to use a generic script for different files or return nifty GIF files of the number of access counts. But they all do the same basic steps, which you've learned about here.
If you're interested in looking at other access counter programs, check out the list on Yahoo at http://www.yahoo.com/Computers/World_Wide_Web/Programming/Access_Counts/, which has several programs, with more being added all the time.
If you've published Web pages that have any degree of popularity, the first thing you're going to notice is that if you move the files to some other machine or some other location on your file system, the links to those pages that got distributed out on the Web never go away. People will be trying to get to your pages at their old locations probably for the rest of your life.
So what should you do if you have to move your pages, either because you reorganized your presentation structure or you changed Web providers?
If you just moved your files around on the disk on the same machine, the best thing to do (if you're on a UNIX system) is create symbolic links from the old location to the new location (using the ln command). This way all your old URLs still work with no work on the part of your reader.
In most cases, you should put a "This Page Has Moved" page on your old server. Figure 27.4 shows an example of such a page.
Figure 27.4 : A "This Page Has Moved" page.
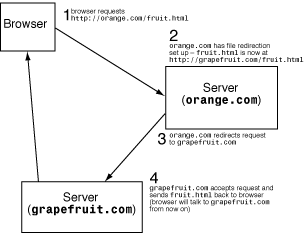
The last option for dealing with files that have moved is to use server redirection. This is a special rule you can set up in your server configuration files that tells the server to redirect the browser to a different location if it gets a request for the old file (see Figure 27.5). Using server redirection provides a seamless way of moving files from one system to another without breaking all the references that are out there on the Web.
Figure 27.5 : How file redirection works.
NCSA HTTPD servers redirect files using the Redirect directive in their configuration files with two arguments: the path to the original set of files as it appeared in the old URL, and the URL to the new files.
In NCSA, the Redirect command looks like this:
Redirect /old/files http://newsite.com/newlocation/files
The first command (/old/files) is the old location of your files, as seen in the URL (minus the http and the hostname). The second part is the new pathname to the new files, and it must be a complete URL. You can use this redirection method for both directories and individual files.
Remember to restart your server after editing any configuration files in order for the changes to take effect.
I mentioned server push briefly in Chapter 9, "External Files, Multimedia, and Animation," as a mechanism for creating very primitive animation in Netscape. Server push has fallen out of favor in recent months with the advent of Java and plug-ins such as Shockwave; in comparison, server push capabilities are often very slow and put an excessive load on the Web server.
However, depending on the affect you want to create, and whether your readers are likely to have Java or not, server push may still have its usefulness.
Usually when a browser makes a network connection to a server, it asks for a page or a CGI script, and the server replies with the content of that page or the result of that script. After the server is done sending the information, the connection is closed.
Using server push, the server doesn't immediately close the connection. Instead, it sends some amount of data, waits some amount of time, and then sends more data. That data can either replace the data it already sent (for example, you can load multiple HTML pages, one right after the other), or with images you can repeatedly fill in a "slot" for an image with multiple images, creating a simple animation.
Server push works with a special form of content-type called multipart/x-mixed-replace. Multipart is a special MIME type that indicates multiple sections of data that may have individual content-types (for example, an HTML file, a GIF file, and a sound file, all as one "package"). File upload using forms uses another form of multipart data. To create a server- push animation, you create a CGI script that sends the initial content-type of multipart/x-mixed-replace and then sends each block of data sequentially. Each block is separated by a special boundary so the browser can tell each block apart.
To send a continuous stream of information to a Web browser by using server push, you need to use CGI scripts similar to those created in Chapter 19. However, instead of starting each Web page you compose by using these scripts with Content-type: text/html, for server push, you need to use a new content-type called multipart/x-mixed-replace.
To find out more about how server push works, we'll convert a simple CGI script-one that prints out the current date and time-to a continually updating Web page that refreshes the time every 10 seconds.
The original script does nothing except use the UNIX /bin/date program to print out the date. Here's the UNIX shell script code for that program:
#!/bin/sh
echo Content-type: text/html
echo
echo "<HTML><HEAD><TITLE>Date</TITLE></HEAD>"
echo "<BODY><P>The current date is: <B>"
/bin/date
echo" </B></BODY></HTML>"
When you run this script, a Web page is created that tells you the current date and time. But now you want to convert this script into a server push system that updates the page regularly.
First, you need to tell the Web browser to start a server push session. To do this, at the start of the new script, write this:
#!/bin/sh
echo "Content-type: multipart/x-mixed-replace;boundary=MyBoundaryMarker"
echo
echo "--MyBoundaryMarker"
The Content-type: multipart/x-mixed-replace; statement on the first echo line informs the Web browser that the following information is part of a multipart stream of data. In addition, boundary=MyBoundaryMarker defines some random text that will be used by the script to indicate when the current block of information is complete, at which stage the browser can display it. As a result, to ensure that the first two echo statements are properly received, the first echo "--MyBoundaryMarker" statement (on the fourth line) is sent to reset the browser.
You now want to create a loop in the script that regularly sends the information contained in the script. You achieve this task by using a shell statement called a while do loop. When coded into the script, it looks like this:
while true
do
Following the do statement, you include the actual script statements to draw the required Web page, like this:
while true
do
echo Content-type: text/html
echo
echo "<HTML><HEAD><TITLE>Date</TITLE></HEAD>"
echo "<BODY><P>The current date is: <B>"
/bin/date
echo" </B></BODY></HTML>"
echo "--MyBoundaryMarker"
Following the body of the script, you need to include a new echo "--MyBoundaryMarker" statement to tell the Web browser that the current page is finished and can now be displayed.
At this stage, you want to tell the script to pause for a short while before sending a fresh page to the browser. You can achieve this action by using sleep 10, which tells the script to pause for 10 seconds. Then after the sleep statement, close the while do loop with a done statement. The done statement tells the script to look back to the preceding do statement and repeat all the instructions again.
When the parts are combined, the final server push script looks like this:
#!/bin/sh
echo "Content-type: multipart/x-mixed-replace;boundary=MyBoundaryMarker"
echo
echo "--MyBoundaryMarker"
while true
do
echo Content-type: text/html
echo
echo "<HTML><HEAD><TITLE>Date</TITLE></HEAD>"
echo "<BODY><P>The current date is: <B>"
/bin/date
echo" </B></BODY></HTML>"
echo "--MyBoundaryMarker"
sleep 10
done
If you save this script in the cgi-bin directory on your Web server and call it using a link to the script, you'll see a Web page that updates every 10 seconds to display a new date and time.
| Note |
For further information about the possible uses of server push-including animation-check the Netscape Communications page devoted to Dynamic Documents, which is located at http://home.netscape.com/assist/net_sites/dynamic_docs.html. |
Each time someone grabs a file off of your server or submits a form, information about the file the person asked for and where the person is coming from is saved to a log file on your server. Each time someone asks for a file with the wrong name, stops a file in the middle of loading, or if any other problem occurs, information about the request that was made and the error that happened is saved to an error file on your server as well.
The log and error files can be very useful to you as a Web designer. They let you keep track of how many hits (defined as a single access by a single site) each of your pages is getting, what sites are most interested in yours, the order in which people are viewing your pages. They also point out any broken links you might have or problems with other parts of your site.
Most of the time, logging is turned on by default. In NCSA's HTTPD, the access_log and error_log files are usually stored in the logs directory at the same level as your conf directory (what's called ServerRoot).
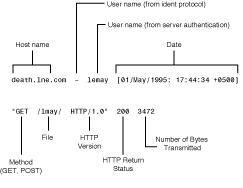
Most servers store their logging information in what is called the common log format, which is common because everyone who uses this format stores the same information in the same order. Each request a browser makes to your server is on a separate line. Figure 27.6 shows what the common log file format looks like. (I've split each line into two here so it'll fit on the page.)
Figure 27.6 : The common log file format.
Here are several things to note about log files:
Caching is the capability of a browser to store a local copy of frequently accessed pages. Depending on how picky you are about how many hits you get on your pages and the order in which they are accessed, caching might produce some strange results in your log file.
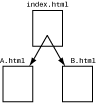
Look at this simple example. You have a very simple tree of files that looks like the one in Figure 27.7. It's not even a tree, really; it's just a home page with two files linked from that home page.
Figure 27.7 : A very simple tree of files.
Suppose someone was going to traverse that tree of yours. Most likely, they would start from the home page, visit page A.html, go back to the index page, and then visit page B.html.
What you might end up seeing in your log file, however, is something like this (I've shortened this sample log file to make it easier to figure out):
reader.com - - [28/Apr/1995] "GET /index.html"
reader.com - - [28/Apr/1995] "GET /A.html"
reader.com - - [28/Apr/1995] "GET /B.html"
According to the log file, your reader went directly from A to B, which should not be possible. Where's the hit back to index.html in between A and B?
The answer is that there was no hit in between A and B. Your reader has a browser that stored a local copy of index.html so that when she left A.html, the local copy was displayed instead of a new version being retrieved from your server.
If you're browsing the Web, having a browser that caches pages can speed things up considerably because you don't have to wait for a page you've already seen to be reloaded over the network every time you want to see it. Caching is also useful for pages that use one image multiple times on the page. Using caching, the browser has to download only one instance of that image and then reuse it everywhere it appears.
If you're watching your logs, however, browser caching might appear to leave holes in your log files where hits should have been, or to actually show you fewer hits on your pages than you would have had if the browser did not do caching.
Even worse are servers that do caching. These are often proxy servers for large companies or online services. If those servers get lots of requests for your page coming from lots of their internal systems or users, they may store a local copy of your pages on their site, again to make pages load faster for someone browsing your pages. You may be getting hundreds of people actually reading your pages but only one hit showing up in your log file.
Caching is one of the bigger problems in trying to get an accurate count of how many people are actually reading your pages. How you handle the holes in your log file, or whether you even care, is up to you. If you're watching your logs for the order in which pages are accessed, you can often fill in the holes where pages should be. If you're concerned about the number of hits to your pages, you can probably add a small percentage based on the pages that would have been accessed without caching.
Or, you can hack your pages so that they are not cached. This is a last-resort hack that may or may not work with all browsers and systems.
Remember the <META HTTP-EQUIV> tag? This is the one you used for client pull presentations in Chapter 9. You can also use it to add a special header that tells the server not to cache the file, like this:
<HTML>
<HEAD><TITLE>My Page, never cached</TITLE>
<META HTTP-EQUIV="Pragma" CONTENT="no-cache">
</HEAD><BODY>
...page content...
</BODY></HTML>
Any page with this tag in it will not be cached by any browsers or proxy servers, which means that it will be reloaded over the network every single time it's seen. Keep in mind that if your pages are slow to load the first time, they'll be slow to load every single time, which may annoy your readers. If you use this special hack to prevent caching of your pages, include it only on important pages (such as home pages) or pages that change frequently.
If you have access to your log file, you can run simple programs on that file to process it and count hits or generate other statistics. For example, the following simple command on UNIX (it also works on SunOS and Linux) prints a list of the number of hits on each file in the log, sorted from largest to smallest (in which access_log is the name of your log file):
awk '{print $7}' access_log | sort | uniq -c | sort -n -r
Figure 27.8 shows some sample output from the preceding command that I borrowed from my server.
Figure 27.8 : The output from the hit-counting command.
What does this do? The first part (starting with awk) extracts the seventh field from the file, which has the filename in it. The sort command sorts all the filenames so that multiple instances are grouped together. The third part of the command (uniq) deletes all the duplicate lines except one, but it also prints a count of the duplicate lines in the files. The last sort rearranges the list in reverse numeric order so that the lines with the greatest counts show up first.
This isn't the most efficient way to parse a log file, but it's simple and almost anyone can do it. Probably the best way to analyze your log files, however, is to get one of the analyzing programs for common log files that are available on the Web. Two of the most popular are Getstats (http://www.eit.com/software/getstats/getstats.html) and Wusage (http://www.boutell.com/wusage/). There's also a list of log file tools at http://www.yahoo.com/Computers/World_Wide_Web/HTTP/Servers/Log_Analysis_Tools/. These programs analyze the contents of your log file and tell you information such as how many hits each page is getting, when during the day the most frequent hits are occurring, the sites and domains that are accessing your pages the most, and other information. Some even generate nifty bar and pie charts for you in GIF form. There's a wide variety of these programs out there. Explore them and see which one works the best for you.
| Note |
Commercial Web servers often have integrated programs for logging and keeping track of usage statistics. See the documentation for your server and experiment with the built-in system to see if it works for you. |
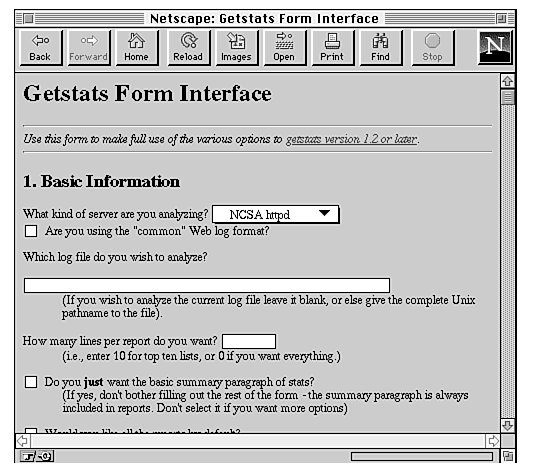
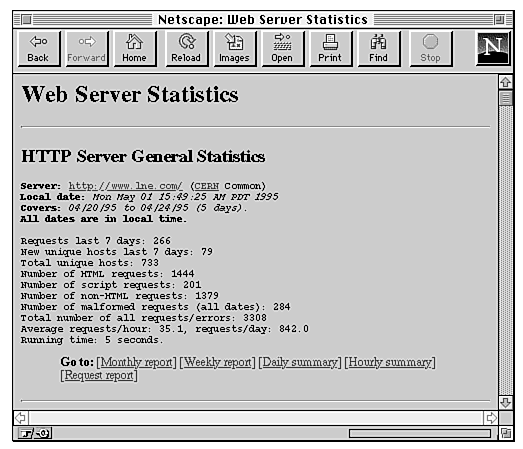
I particularly like Getstats because it comes with a form so that you can run it from your Web browser. Figure 27.9 shows the form, and Figure 27.10 shows the output.
Figure 27.9 : The Getstats form.
Figure 27.10 : The report generated by Getstats.
Some servers give you the ability to store extra information about each hit to your pages, including information about which browser was used to access that file and information about the page where the link came from. Those bits of information are called user-agents and referrers, respectively, after the HTTP headers that communicate this information about browsers to the servers.
Why would you be interested in this information? Well, user-agents tell you the kind of browsers that are accessing your files. If you want to know how many of your readers are using Netscape 2.0 (to perhaps adjust your pages to take advantage of Netscape 2.0 features), the user-agent data will tell you this (Netscape calls itself "Mozilla" in the user-agent data). It'll also tell you the platform the browser was being run on and the version of the browser being used.
| Note |
User-agents are the type of browsers that are accessing your files, includ-ing the browser name, the version, and the plaform it is running on. |
Referrers are often even more interesting. The referrer page is the page the browser was viewing just before readers loaded one of your pages. What this usually means is that there was a link on that referrer page to your pages. Referrer logs let you see who is linking to your pages. You can then visit those pages and see if they're saying nice things about you.
| Note |
Referrers are the pages the browser was visiting before they visited one of your pages-often the referrer pages contain links to your pages. |
Log file analyzers are available for keeping track of user-agent and referrer statistics; a general log file analyzer may be able to produce summaries of this information as well. NCSA keeps a good list of user-agent and referrer log analyzers at http://union.ncsa.uiuc.edu/HyperNews/get/www/log-analyzers.html.
If you have access to your own Web server, configuring that server in different ways can enable you to provide features in your presentations that pure HTML cannot provide. Features such as server-side includes can add bits to your HTML files on-the-fly, allowing you to automatically update files and let the server do the work in many cases. Redirecting files enables you to move files around on your server without breaking all the links. Server push allows dynamically updateable documents. Finally, by watching and analyzing your log files, you can keep track of who is reading your pages, when, and in what order.
In this chapter, you've learned how to do all of these things. But don't stop here. I've covered only a few of the features that your Web server can provide. Dive into your server documentation and find out what your server can do for you.
| Q | I have a .shtml file with two include statements that run CGI scripts. Both of those CGI scripts need arguments. But, from what you said in the section on server includes, I can't pass arguments in the include file. I have to include them in the URL for the .shtml file itself. How can I pass arguments to each of the included CGI scripts that way? |
| A | The only way I can think of to do this is to pass all the arguments for all the included CGI scripts as part of the URL to the .shtml file, and then make sure your CGI scripts know how to parse out the right arguments in the argument string. |
| Q | I can run normal includes, such as #include and #fsize, but not #exec includes. I just get errors. What's going on here? |
| A | It's possible that your server administrator has disabled exec includes for security reasons; you can do this in the NCSA HTTPD. I suggest you ask and see what he or she has to say on the matter. |
| Q | I don't have access to my log files. My Web server is stored on an unaccessible machine. How can I get information about my pages? |
| A | Usually your Web server administrator will have some method for you to access the log files-perhaps not directly, but through a program or a form on the Web. The administrator might even have a statistics program already set up for you so that you can find out the information you want. At any rate, you should ask your Web server administrator to see what methods are available for getting your logs. |
| Q | I run a popular Web site with information that is updated daily. Recently I've been getting complaints from folks on a large online service that they're not getting updated pages when they view my site. What's going on here? |
| A | Most of the big online services use caching servers, which, as I noted earlier, means that they store local copies of your pages on their server for use by their customers. Given that their customers are often on
very slow modem connections, and that your pages have to go from your site through their site to a local hub to their customer's system, caching is a good idea because it cuts down on the time that pages would ordinarily take to load.
Caching servers are supposed to check back with your server every time there's a request for your page to make sure that the page hasn't changed (if it hasn't, they just use the local copy; if it has, they're supposed to go get the new one). However, the caching servers for the online services are notorious for not doing this very well and for keeping obsolete pages around for weeks or months. The solution for your readers on those online services is for them to use the Reload button in their browsers to go get the real version of the page (reload is supposed to bypass the server cache). You might want to add a note to this effect on your pages so that readers know what to do. |