{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




connect \k-'nekt\ v: to join or fasten together
A computer application is nothing more than a bundle of source code that manipulates a set of data. That data is key to the operation and functionality of the application. The data, however, can come from a variety of places. Be it user entered, in-memory defaults, or offline stored databases, these databases and their relationship to Java are the subject of this chapter.
In this chapter I'll cover the following topics:
This chapter will set the stage for developing our database framework and the database applications later in the book.
Databases come in all different shapes and sizes. They can be flat files of ASCII data (like Q&A) or complex binary tree structures (Oracle or Sybase). In any form, a database is a data store, or a place that holds data. The type of data that is contained in the store is irrelevant.
If a database is simply a collection of data, then what keeps
track of changes to this data? That is the job of the database
management system, or DBMS. Some DBMSs are relational.
Those are RDBMSs. The relational part refers to the fact that
separate collections of data within the reaches of the RDBMS can
be looked at together in unison. The RDBMS is responsible for
ensuring the integrity of the database. Sometimes, things will
get out of whack and the RDBMS will keep all that data in line.
| Note |
Very few DBMSs are not RDBMSs these days. We will refer to any database, be it DBMS or RDBMS as RDBMS for the remainder of this chapter and book. |
There are so many different types of RDBMSs available today that it would probably take two full books to give a summary of each one. This overview is a quick start guide for those of you who are not familiar with some newer concepts in data storage.
In the days of yore, programming database applications was pretty simple. There were mainframe databases and there were very few microcomputer databases available. The ones that were available cost an arm and a leg. The cheap ones were, well, you got what you paid for. But you always had database files, records, and fields.
The database terms of yesteryear, however, have been replaced by new ones. Some of the bigger database companies like Oracle and Sybase have redefined database terminology. The main thrust of this redefining is most likely in response to the larger customer base that is not "programming-literate."
A programmer can deal with files, records, and fields. But more and more non-technical people are creating database applications and queries these days. Their formal training is through the use of applications. As you'll see, some of the new terms are commonly found in spreadsheet and word processing programs.
The following is a list of current database terms that will be used in the rest of this chapter and throughout the book:
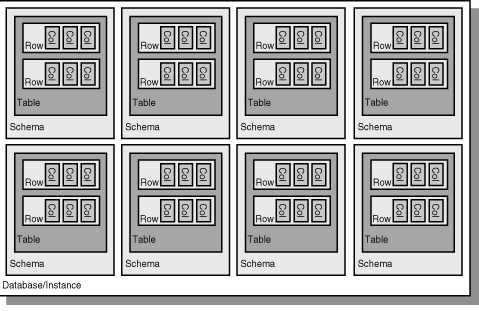
Figure 6.1 is a visual representation of the preceding terminology.
Figure 6.1 : A visual guide to the database terminology used in this book.
Databases can exist in various places. Larger databases require the horsepower of a multiple CPU server. Smaller databases can get away with only a microcomputer serving data. But where the data is stored is important to the application programmer. There are only two options for database location: local and remote.
A local database is one that resides on the machine on which client applications run. Local databases offer the fastest response time because there is no network traffic between the client (your application) and the server (the RDBMS engine). Some examples of local databases are Paradox from Borland, Access from Microsoft, and Personal Oracle from Oracle.
A remote database, on the other hand, is one that resides on a machine that the client software does not run on. This is an important distinction for two reasons:
The first item is the general case. It is also only relevant for performance-critical applications. A well-tuned RDBMS server can out-perform a poorly tuned local server in some cases.
The second item, however, might cause grief and headaches that
weren't expected. With some database server and client products,
a second software layer is necessary to transparently interact
with the remote database. This software might be an optional software
package that is not included with the server software. I'll get
to this layer in the next topic, "Database Access."
| Tip |
Here are some of the database software vendor Web sites, and some excellent sources of database information:
|
There is one more topic I'd like to touch upon before I get into accessing databases: it is the client-server concept of multi-tiering. Unfortunately, I have heard about ten different explanations of this concept and not one of them ever is the same. The following is my take on the single-, two- and three-tiered architectures.
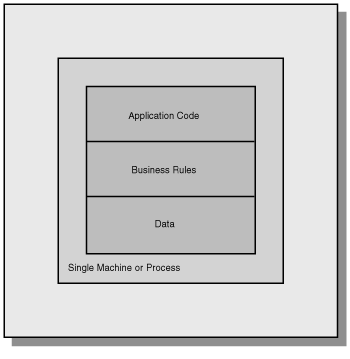
The application and the data reside together logically. These are not usually database programs. An example would be a calculator program. The logic and its data reside together. Figure 6.2 shows a model of a single-tier application.
Figure 6.2 : A single-tier application.
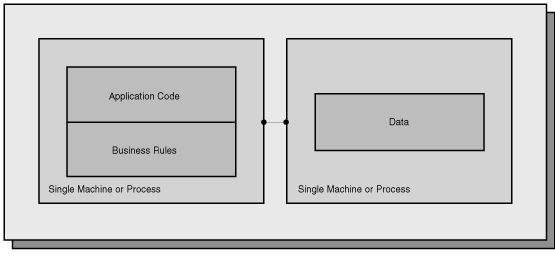
The application resides in a different logical location than the data. These are usually database applications. Most client/server applications fit into this category. Figure 6.3 shows a model of a two-tier application.
Figure 6.3 : A two-tier application.
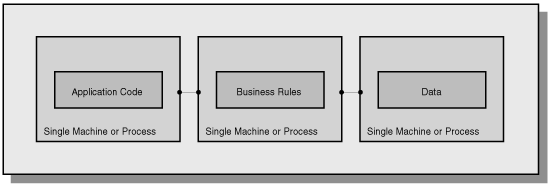
In a three-tiered system, the application resides in a different logical location than the logic of the application and the data.
To put it another way, the client software makes a call to a remote service. That remote service is responsible for interacting with the data and responding to the client. The client has no knowledge of how and where the data is stored. All it knows about is the remote service. Conversely, the remote service has no knowledge of the clients that will be calling it. It only knows about the data.
This partitioning of logic allows for better data control and reuse of existing code. Three-tier architecture is becoming more widespread because more and more tools are being created that handle the tiering automatically.
Figure 6.4 shows a model of a three-tier application.
Figure 6.4 : A three-tier application.
In order to "talk" to your database you need to use some sort of software. Whether it comes with your server or you have to write the code yourself, this software is essential for database communications.
Although there are innumerable methods of retrieving and storing data, the following are the most common: native, ODBC, and SQL. SQL is probably the most common data access method, ODBC a close second, and, except for driver creators, native methods are rarely used. Figure 6.5 illustrates the software layers in the three methods outlined.
Figure 6.5 : The software layers that can be used to access data.
The following is a short discussion on each of the three access methods.
Native drivers give you the raw power of talking directly to your database. When you make the connection and retrieve data, you are talking right to the file system. An example of a native driver is the Oracle Call Interface, or OCI from Oracle Corporation for Oracle databases.
Native drivers are usually statically or dynamically linked into your software at compile time.
Open Database Connectivity, or ODBC, is a standard developed by Microsoft Corporation. ODBC is an application program interface for accessing data in a standard manner from an abundance of data sources regardless of their type. If the data source is ODBC compliant, your program can talk to it.
ODBC drivers are available for almost every major database vendor.
| Tip |
Check out the ODBC Homepage for some cool ODBC links! |
Although not a "layer" of access to databases like ODBC or native drivers, the Structured Query Language, or SQL, provides a standard method of querying data from different data sources.
SQL, usually pronounced like the word "sequel," was adopted as an industry standard in 1986. SQL was completely overhauled in 1992 and the new language was called SQL92, or SQL2. Work is currently in progress to produce the next generation, SQL3. The following is a short list of SQL commands and their meanings:
We'll go over the syntax of some of the more commonly SQL commands.
Just a reminder, though, that this is by no means an exhaustive
SQL syntax review. Dozens of books about SQL have been published.
The command syntax that follows is general ANSI SQL and might
not be correct for your RDBMS. Please check your documentation
if there is any doubt.
| Note |
In the syntax examples that follow, any parameter that is enclosed in square brackets ([]) is an optional parameter and may be left out. |
Most SQL commands act on all the rows of a table at one time. These global actions can be restricted to a limited number of rows by the use of a WHERE clause. The WHERE clause allows you to specify criteria that is used to limit the number of rows that an action is performed.
The general syntax for a WHERE clause is as follows:
COMMAND arguments WHERE [[[schema.]table.]column OPERATOR value] [AND|OR [[[schema.]table.]column OPERATOR value]]
where
arguments are the arguments specific to the COMMAND.
schema is the area where the table exists.
table is the table where the column lives.
column is the column name to compare with value.
value is a literal or column name to compare with column.
Multiple operations may be checked in the WHERE clause. These can be linked with either the AND or OR keyword.
The OPERATOR might be many
things depending on the RDBMS in use. Table 6.1 shows the OPERATORs
that are available in most RDBMSs.
| Operator | Meaning | Example |
| < | Less than | emp_id < 10 |
| > | Greater than | salary > 50000 |
| = | Equal to | can_be_paged = 'Y' |
| <= | Less than or equal to | user_count <= 128 |
| >= | Greater than or equal to | user_count >= 0 |
| <> | Not equal to | lost_shovels <> 5 |
| is | For checking NULL values | name_suffix is NULL |
| not | For negating an operator | name_suffix is not NULL |
| like | Allows for the use of wildcards | first_name like '%MUNSTER%' |
Please note that the WHERE clause cannot be used alone. It must be appended to a DELETE, SELECT, or UPDATE command.
The INSERT statement allows you to create a new row in a table.
The syntax for an INSERT statement is as follows:
INSERT INTO [schema.]table [(column[,column…])] VALUES (value[,value])
Where:
schema is where the table exists
table is the target table
column is the column name(s) of the data you wish to insert
value is the value(s) that you wish to insert
INSERT INTO EMPLOYEE ( EMP_ID, LAST_NAME ) values ( 1, 'Munster' )
INSERT INTO ADDRESS ( EMP_ID, STREET_ADDRESS ) VALUES
¥ ( 1, '1313 Mockingbird Lane' )
The DELETE statement allows you to remove a row or rows from a table.
The syntax for a DELETE statement is as follows:
DELETE FROM [schema.]table [WHERE expression]
where
schema is where the table exists
table is the target table
expression is an expression as outlined in the preceding WHERE clause section
| Caution |
Without a WHERE clause, the DELETE command removes all rows from a table. |
DELETE FROM EMPLOYEE WHERE EMP_ID = 1
DELETE FROM ADDRESS WHERE CITY LIKE 'chICAG%'
The SELECT statement allows you to retrieve a row or rows from a table.
The syntax for a SELECT statement is as follows:
SELECT [[schema.]table.]column [,[[schema.]table.]column] FROM [schema.]table [WHERE expression]
where
schema is where the table exists
table is the target table
column is column or columns to retrieve. You can use the asterisk ('*') to indicate that the SELECT statement should return all columns.
expression is an expression as outlined in the preceding WHERE clause section
SELECT EMP_ID FROM EMPLOYEE
SELECT LAST_NAME, FIRST_NAME, MID_NAME FROM EMPLOYEE WHERE EMP_ID = 666
The UPDATE statement allows you to modify a column or columns in one or more rows in a table.
The syntax for an UPDATE statement is as follows:
UPDATE [schema.]table SET [[schema.]table.]column = value [,[[schema.]table.]column = value] [WHERE expression]
where
schema is where the table exists
table is the target table
column is column or columns to modify
expression is an expression as outlined in the preceding WHERE clause section
value is the new value that the column should hold
UPDATE EMPLOYEE SET SALARY = SALARY + ( SALARY * .05 )
UPDATE ADDRESS SET ZIP_CODE = 60805 WHERE ZIP_CODE = 60642
SQL uses simple English words to instruct the database to perform
certain actions. SQL can be used with almost every major database
product available today. In addition, you can even use SQL syntax
to interact with a data source using ODBC!
| Tip |
Here are some useful SQL Web sites:
|
Java is a platform independent programming language. In order to access a database with Java you need to use a platform-independent method. This is easy to accomplish, but might be quite cumbersome. Usually, you'd have to create a server program that speaks to the database of your choice and then your Java programs would need to interact with your server.
If you want to abandon your platform independence, you can always write native code to access your data. This would involve C or C++ programming in UNIX or Windows 95/NT. Without the proper tools, this can be a real headache.
So what does a programmer do when he needs data access from Java? There are several ways to get data to your application. These database access services include:
The latest arrival onto the database scene is Sun Microsystem's own Java Database Connectivity, or JDBC. JDBC is big news and I'll get into that in a bit. But for now, let's take a closer look at these other data access options.
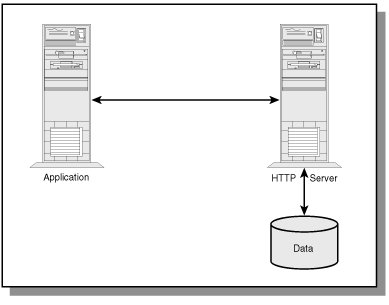
To access data via CGI scripts, the applet or application requests data from an HTTP server just like any other Web document. However, encoded in the CGI parameters is the database query that is to be executed. Once the HTTP server receives the request, it passes the parameters to the proper CGI program. The CGI program then performs the database query on the program's behalf.
Because this is a three step process, response time is not fantastic. But if the HTTP server is on the same machine as the application and the database, response times are better. Figure 6.6 illustrates a typical database access method via a Web server.
Figure 6.6 : Database requests through HTTP and CGI.
This option is useful for specific types of databases that cannot be moved or can only live on certain types of environments.
Of note is Oracle's WebServer product, which can access Oracle databases directly without going through a CGI program. Using the WebServer, you can embed database requests right in your HTML pages. Once these pages are received by the Oracle WebServer, they are parsed, and recreated on-the-fly. The recreated pages include, for instance, data from an Oracle database. This seamless integration removes the need for a separate CGI program to access data. This is a lot faster and is a complete database solution.
Here are some CGI/HTTP database access solutions available for Java:
Another Java database option is going with a proprietary server. In this access mode, a non-Web server listens for service requests. Once one is received, it will perform a database query on the client's behalf and return the results to the client.
Here are some proprietary server database access solutions available for Java:
Network access database solutions for Java are the best. These provide platform independence because the actual network connection and requesting is done in Java.
Here are some network database access solutions available for Java:
Direct access is probably the fastest method of database access, however it is the least portable. You could possibly lose any platform independence you've gained by using Java in the first place. However, if you don't care about independence, this method of database access is by far the best performance-wise.
Here are some direct database access solutions available for Java:
In an effort to set an independent database standard API for Java, Sun Microsystems developed Java Database Connectivity, or JDBC. JDBC offers a generic SQL database access mechanism that provides a consistent interface to a variety of RDBMSs. This consistent interface is achieved through the use of "plug-in" database connectivity modules, or drivers. If a database vendor wishes to have JDBC support, he or she must provide the driver for each platform that the database and Java run on.
To gain a wider acceptance of JDBC, Sun based JDBC's framework on ODBC. As you discovered earlier in this chapter, ODBC has widespread support on a variety of platforms. Basing JDBC on ODBC will allow vendors to bring JDBC drivers to market much faster than developing a completely new connectivity solution.
JDBC was announced in March of 1996. It was released for a 90 day public review that ended June 8, 1996. As a result of user input, the final JDBC v1.0 specification was released soon after.
The remainder of this section will cover enough information about JDBC for you to know what it is about and how to use it effectively. This is by no means a complete overview of JDBC. That would fill an entire book.
Few software packages are designed without goals in mind. JDBC is one that, because of its many goals, drove the development of the API. These goals, in conjunction with early reviewer feedback, have finalized the JDBC class library into a solid framework for building database applications in Java.
The goals that were set for JDBC are important. They will give you some insight as to why certain classes and functionalities behave the way they do. The eight design goals for JDBC are as follows:
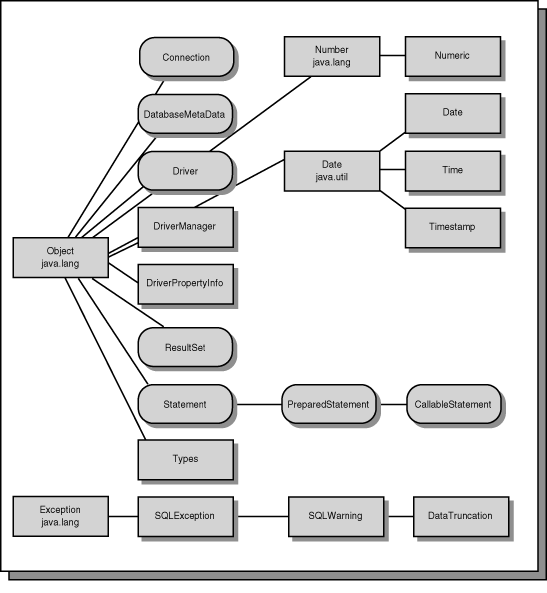
JDBC is divided into two parts: The JDBC API, and the JDBC Driver API. The JDBC API is the programmer's API. This half is where you will spend most of your time coding. The JDBC Driver API is for driver writers and database vendors to create connectivity modules for their database software. Figure 6.7 shows the complete JDBC API class hierarchy.
Figure 6.7 : The JDBC class hierarchy.
The JDBC API consists of many classes and interfaces. This structure makes the API a semi-abstract set of functionality. In order for JDBC to be of any use, a database vendor must fill in the blanks.
Four of these blanks will be the center of any database programming that you do with the JDBC API. These four classes are
This short overview is only a small portion of the JDBC API. There is support for other database features such as cursors and stored procedures.
Many database vendors have already pledged support of JDBC. The following is a list of vendors who plan on supporting JDBC. This list is from the JDBC Web site as of June, 1996.
Most big database vendors are on this list. If your database vendor is not on this list, fear not. There will be a JDBC-ODBC bridge driver from Sun. If your database vendor has ODBC support, then you will be in the clear.
For more information on JDBC, please visit the JDBC Web site at JavaSoft: http://www.javasoft.com.
This chapter was an overview of databases and database connectivity options that you have at your disposal. I discussed the database terminology that you will be using in the book for the first time. You are now familiar with rows and columns of data. The more you use these terms, the more comfortable you will be using them (it took me nearly 6 months!).
After the terminology discussion, I talked about the differences between local and remote databases. This led you right to a discussion about the advantages and disadvantages of various database access methods.
Finally, I ended this chapter discussing Java Database Connectivity, or JDBC. JDBC is the hot, new, up-and-coming database connectivity tool for Java.