| |
Top Contents Index Glossary |
|
Link Summary
|
|
By now, you understand the structure of the nodes that make up a DOM. A DOM is actually very easy to create. This section of the DOM tutorial is going to take much less work than anything you've see up to now. All the foregoing work, however, generated the basic understanding that will make this section a piece of cake.
In this version of the application, you're still going to create a document builder factory, but this time you're going to tell it create a new DOM instead of parsing an existing XML document. You'll keep all the existing functionality intact, however, and add the new functionality in such a way that you can "flick a switch" to get back the parsing behavior.
Note:
The code discussed in this section is in DomEcho05.java.
Start by turning off the compression feature. As you work with the DOM in this section, you're going to want to see all the nodes:
public class DomEcho05 extends JPanel
{
...
boolean compress = true;boolean compress = false;
Next, you need to create a buildDom method that creates the document
object. The easiest way to do that is to create the method and then copy the
DOM-construction section from the main method to create the buildDom.
The modifications shown below show you the changes you need to make to make
that code suitable for the buildDom method.
public class DomEcho05 extends JPanel
{
...
public static void makeFrame() {
...
}
public static void buildDom ()
{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder = factory.newDocumentBuilder();
document = builder.parse( new File(argv[0]) );} catch (SAXParseException spe) {...} catch (SAXException sxe) {...} catch (IOException ioe) {...
In this code, you replaced the line that does the parsing with one that creates a DOM. Then, since the code is no longer parsing an existing file, you removed exceptions which are no longer thrown: SAXParseException, SAXException, and IOException.
Finally, since you are going to be working with Element objects, add the statement to import that class at the top of the program:
import org.w3c.dom.Document; import org.w3c.dom.DOMException;import org.w3c.dom.Element;
Now, for your first experiment, add the Document operations to create a root node and several children:
public class DomEcho05 extends JPanel
{
...
public static void buildDom ()
{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
try {
DocumentBuilder builder = factory.newDocumentBuilder();
document = builder.newDocument(); // Create from whole cloth
Element root =
(Element) document.createElement("rootElement");
document.appendChild (root);
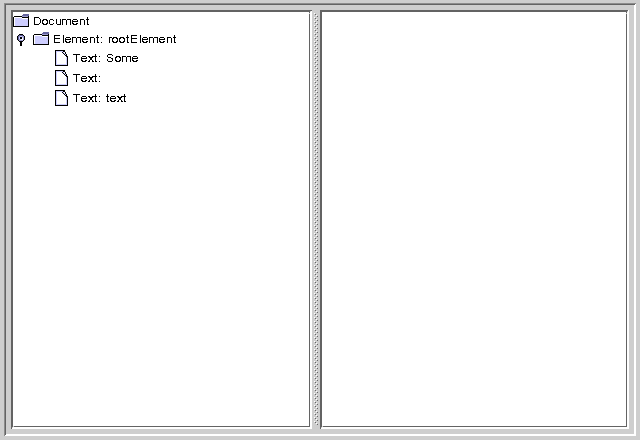
root.appendChild( document.createTextNode("Some") );
root.appendChild( document.createTextNode(" ") );
root.appendChild( document.createTextNode("text") );
} catch (ParserConfigurationException pce) {
// Parser with specified options can't be built
pce.printStackTrace();
}
}
Finally, modify the argument-list checking code at the top of the main method so you invoke buildDom and makeFrame instead of generating an error, as shown below:
public class DomEcho05 extends JPanel { ... public static void main (String argv []) { if (argv.length != 1) {System.err.println ("Usage: java DomEcho filename");System.exit (1);buildDom(); makeFrame(); return; }
That's all there is to it! Now, if you supply an argument the specified file to be parsed and, if you don't, the experimental code that builds a DOM is executed.
Compile and run the program with no arguments produces the result shown in Figure 1:
Figure 1: Element Node and Text Nodes Created
In this experiment, you'll manipulate the DOM you created by normalizing it (cf. normalization) after it has been constructed.
Note:
The code discussed in this section is inDomEcho06.java.
Add the code highlighted below to normalize the DOM:.
public static void buildDom ()
{
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
try {
...
root.appendChild( document.createTextNode("Some") );
root.appendChild( document.createTextNode(" ") );
root.appendChild( document.createTextNode("text") );
document.getDocumentElement().normalize();
} catch (ParserConfigurationException pce) {
...
In this code,
Figure 2: Text Nodes Merged After Normalization
Here, you can see that the adjacent text nodes have been combined into a single node. The normalize operation is one that you will typically want to use after making modifications to a DOM, to ensure that the resulting DOM is as compact as possible.
Note:
Now that you have this program to experiment with, see what happens to other combinations of CDATA, entity references, and text nodes when you normalize the tree.
To complete this section, we'll take a quick look at some of the other operations you might want to apply to a DOM, including:\
The org.w3c.dom.Node interface defines a number of methods you can use to traverse nodes, including getFirstChild, getLastChild, getNextSibling, getPreviousSibling, and getParentNode. Those operations are sufficient to get from anywhere in the tree to any other location in the tree.
The org.w3c.dom.Element interface, which extends Node, defines a setAttribute operation, which adds an attribute to that node. (A better name from the Java platform standpoint would have been addAttribute, since the attribute is not a property of the class, and since a new object is created.)
You can also use the Document's createAttribute operation to create
an instance of Attribute, and use an overloaded version of setAttribute
to add that.
To remove a node, you use its parent Node's
removeChild method. To change it, you can either use the parent
node's replaceChild operation or the node's setNodeValue
operation.
| |
Top Contents Index Glossary |