{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




Because most of the Internet technology and concepts we will be talking about are based on Internet applications and how they can be used to develop an intranet, you must first understand client/server technology-the basis on which the Internet is built. When you understand client/server technology, you will understand better many of the concepts and ideas discussed here and how to expand on them. Let's begin by discussing how computers first became connected to each other and how client/server technology grew from there.
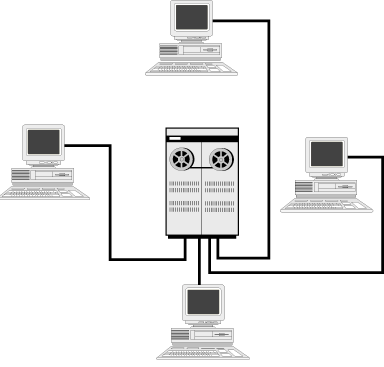
Before the advent and widespread use of the personal computer (PC) in the early 1980s, businesses and government relied on mainframe computers for information technology. The mainframes had the capacity to compute but were slow and could handle only a limited number of users. Mainframe users were tied to small "dumb terminals," essentially keyboards and monitors with no capacity to compute or process information. Information was entered and received at the dumb terminals but processed on the mainframe machine. Figure 4.1 illustrates mainframes and dumb terminals.
These early mainframes were large machines, often taking up an entire room. They looked nothing like today's sleek PCs or compact laptop computers, which conveniently fit into briefcases. In fact, technology has come so far in such a short time, it's likely that the operator, who in the 1960s and 1970s conducted his or her work holed up in a room with a mainframe, now performs similar work on a laptop-capable of handling and processing at least as much information-while he or she travels around the country, or even the world!
By 1985 the PC arrived in the serious business environment. This computer could perform all the functions of the mainframe-right on the desktop. PCs could process databases and spreadsheets, and their word processing features were the death knell for typewriters. These computers were fast compared with the mainframe, which usually was slowed due to the number of users logged on from the individual dumb terminals. Now, each user had his or her own machine.
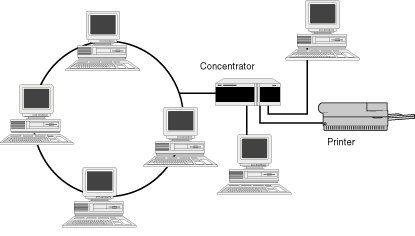
But for all the new functions they could handle, the first PCs still had a long way to go. Data exchange was difficult. To share information among other PCs and users, files had to be copied onto floppy disks and then physically installed in the disk drives of other PCs. A partial solution to this drawback came with the local area network (LAN). With a LAN, computers in the same building could communicate with one another through wiring, as shown in Figure 4.2.
Figure 4.2: An ethernet LAN interconnects PCs in the same building using wiring and a concentrator.
Now users could share files without having to physically install them in each PC; however, only one person could work on a file at one time. Although users could share files, they still could not easily exchange data. This was inefficient for businesses, and organizational problems arose. For example, if an organization with several salespeople wanted to track sales, each salesperson had to keep a separate sales data file. When it was time to look at the complete sales picture, each salesperson's file had to be merged with the other files to obtain effective and accurate data. Because of this inconvenience, much of the data was compiled and stored on paper, which was more expensive in materials and labor costs.
Internal communications for businesses and the government became easier with the advent of internal e-mail in the late 1980s. This eased communications within a building. But what was being done to allow these businesses and the government to communicate with other businesses or agencies across town, on the other coast, or even in another country?
In the continuing evolution of computer communications, the modem arrived on the scene in the 1970s but did not gain widespread appeal until the mid-1980s. Finally, computers in remote locations-countries, coasts, or continents away-could connect with each other. This made it easy for two individuals at a time to exchange files with each other and even to chat online. This initial modem connection was linear, and therefore limited in scope, as only two users could take advantage of one connection.
Bulletin board system(BBS) software was created to enhance the modem's capabilities (see Figure 4.3). Now, individuals could connect to other computers in remote locations, albeit excruciatingly slowly and with much patience and technical know-how. Thus began the first forms of remote digital exchange. Businesses used BBS technology to provide technical support to clients and employees. Hobbyists and interest groups utilized the technology as a new, faster means of communication. Whereas the modem enabled a site-to-site or computer-to-computer connection, bulletin boards enabled computers to communicate and exchange information through this connection. Now, instead of a person-to-person connection, it was much like today's conference call, with many users from remote sites congregating in a common cyberarea.
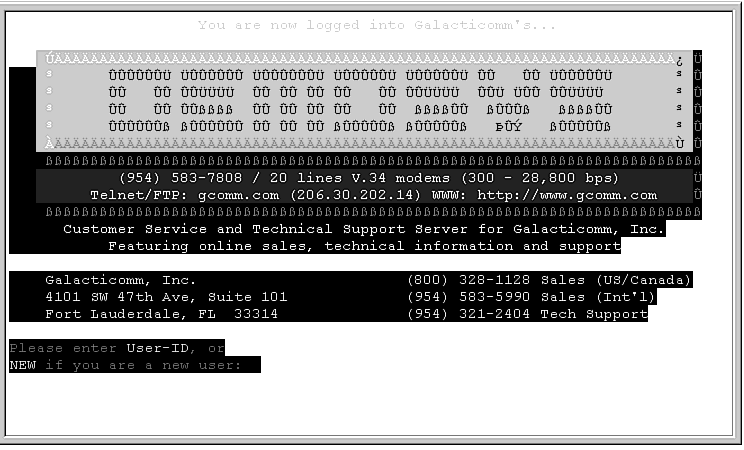
BBS software was one of the first vestiges of client/server applications. Initial client/server technology consisted of a main computer, operated by the systems operator, or sysop, which was capable of connecting several hundred modems. At the other end of the connection was the individual user's machine, with its single modem. The user dialed the BBS from its single modem and connected to one of the BBS's modems. At first, users had to type in arcane commands to accomplish everything from communicating and processing information to searching and retrieving data, as shown in Figure 4.4. Later came graphical interfaces, first with ASCII characters and then with graphic files.
Figure 4.4: BBSs have a variety of interfaces, such as this ASCII interface.
BBSs were one of the first communications tools to deal with the issues of cross-platform computing. Because there was no common operating system, or language, the BBS sysop did not know what type of computer was connecting with it. To further complicate the connection, at this time there was a larger variety of computers on the market and in use than there are today. Atari, Commodore, Amiga, Texas Instruments, as well as Apple and IBM, were all popular home PCs at that time. Each had their own operating systems and configurations. The BBS operator's task was to construct a common interface so that it could communicate with any computer. One of the first such interfaces, and one that remains prevalent in terminal connections today, was ANSI/VT-100. With VT-100, any computer anywhere could connect to a BBS and get a common interface.
The first BBSs performed only limited functions, mainly providing an area for uploading or downloading files and e-mail. As the software grew more complex, more functions were added, such as message boards. Here users carried on conversations by posting and replying to messages on a range of topics. As BBSs became more popular and host computers became more powerful, with the capability to handle more connections, users began to "chat" in real time. This allowed multiple users to "speak" with each other at the same time. Chatting in real time allowed users to have a dynamic rather than a static conversation. Some users even played games with each other over BBSs.
Businesses, mostly computer related, started using BBSs to provide computer files such as drivers, patches, and upgrades to their customers and to handle technical support. With message boards, a technical support question only had be answered once and then was posted for any user to access. Now any user could find answers to common questions without tying up phone lines or expensive human technicians. BBSs were created on a simple theory: Place a reservoir of information on a single computer, make it accessible to the world, and let it be a meeting place for the exchange of information and ideas.
The server aspect was the key to BBSs' success in the age of the modem. It enabled users to log on once a day or once a month to retrieve their e-mail, new files, or new message board postings. The information was stored on the server for the individual user to retrieve at his or her leisure; an expensive constant or direct connection was not necessary.
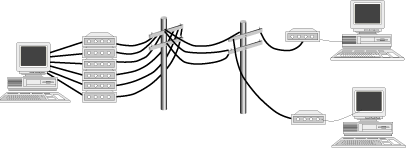
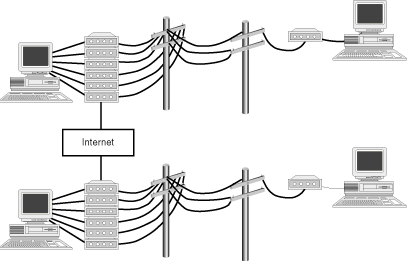
Shortly after BBSs became the main avenue for computer communications, BBSs started connecting to each other and to the Internet in the late 1980s and early 1990s. Now, in addition to exchanging e-mail and files with other users on a single BBS, the Internet and multiple BBSs enabled users to perform these functions with many users (see Figure 4.5). At first, it was set up in multilevel client/server fashion. The BBS functioned as a server for its individual users but as a client for the Internet as a whole. The first BBSs to connect to the Internet did so through a modem connection to an Internet service provider that sent and downloaded the user's mail a few times a day.
Figure 4.5: Two BBSs connected through the Internet serving client computers over modems.
In 1995, Boardwatch BoardWatch magazinemagazine listed more than 30,000 bulletin board systems in the United States.
From the large and isolated mainframe and the first desktop PCs of limited data exchange evolved today's PCs, which allow users to create files and applications and to communicate and share those files with users worldwide. E-mail as we know it today was born from these initial BBSs.
BBSs launched a desire for more sophisticated nationwide networks. In the late 1980s, services like CompuServe, America Online, and Prodigy were created to tap into the growing pool of bulletin board users. While these advanced applications began to satisfy and convert bulletin board users to their services, their other features piqued the interest of many would-be users. With access to features like up-to-the-minute news, access to local phone numbers nationwide, a growing user base, libraries, and chat groups, people soon realized they could utilize their computers-at the office and at home-quickly and easily to communicate worldwide. Their computers offered a world of resources, literally, at their fingertips.
While people at work and at home were scurrying to sign up with an online software program, the Internet began to expand beyond its exclusive service as a military function.
One of the Internet's first stops after its military service was in educational institutions. Universities found the Internet especially useful in exchanging research data, ideas, and papers and began exchanging files, data, and findings with other campuses worldwide.
Researchers, however, did not need to set up separate computers to host their data or to serve as a common place to store the information; they already had powerful computers that were connected to the Internet. What was needed, however, was a way to host the data and an established protocol for requesting and receiving information in an organized and efficient manner. Server computers called daemons became the hosts for an Internet protocol. The first daemons were mail and file transfer protocols (FTPs). The FTP daemon waited for the user to request a file. When a file was requested, the daemon started the processes necessary to answer a request. Somewhat like the postal worker who sorts snail mail, the mail daemon waited for mail to arrive, processed that mail, and then forwarded it to a local mailbox or a remote site, where it was delivered to the user.
The idea of an interconnected computer network capable of supporting multiple users with simultaneous access to the same information had long been proposed by scientists who recognized its research potential even before technology made it possible.
The evolution of the Internet dates from the 1960s, with the development of packet-switched networks-messages fragmented into smaller parts. These subparts, or packets, were discrete data units routed and reassembled at the other end of a transmission, permitting several users to share the same connection.
Packet-switched networks took computing from a client/server model to peer-to-peer networks, a development that would ultimately replace the large, centralized mainframe systems with the decentralized systems represented by today's PCs.
In 1969 an early packet-switched network was implemented at the U.S. Department of Defense's Advanced Research Projects Agency (DARPA). In 1982 the ARPANET, as it was called, replaced its original Network Control Protocol (NCP) with the Transmission Control Protocol (TCP) and Internet Protocol (IP). Used together, the TCP/IP suite of communications protocols connects a set of networks, now widely referred to as the Internet.
In the early 1980s, a meeting of DARPA, the National Science Foundation, and scientists from various universities yielded the development of the Computer Science Research Network (CSNET). CSNET and ARPANET were later connected through a gateway called the VAN (Value Added Network). The VAN, coupled with free access to TCP/IP, heralded the beginning of what is now known as the Internet.
Client/server architectures such as the user-created UNIX User Network (Usenet) implementing the Unix-to-Unix Copy Protocol (UUCP) and the Because It's Time Network (BITNET) also emerged in the early 1980s as homegrown alternatives to ARPANET. These networks used off-the-shelf technology in innovative ways, and their users, initially university researchers, have grown into sizable, diverse populations who exchange e-mail, engage in wide-ranging, free-style discussions and subscribe to a countless number of subject areas.
As PCs evolved and users became more sophisticated and hungry for even more information, there developed a need for a new type of computer: the server. A server is a piece of hardware that receives, processes, and replies to a query. It usually is or resides on a central computer. A server has the capability to handle multiple connections concurrently and from many different sources or clients. Traditionally, server hardware is in the form of powerful minicomputers. More recently, however, high-end PCs are being used as servers in many functions.
A client is a computer or software application that helps a user form and send a query and then displays the results of the queried information for the user. Practically any computer can be a client; in fact, most servers have client software installed on them as well.
Like automated teller machines (ATMs), client/server applications are based on transactions. The client sends a request to the server, similar to a customer sending a request to an ATM. Just as the outcome of the ATM transaction depends on what type of information the customer gives the ATM when prompted, so does the outcome of a client request for information from a server depend on the information given to the server.
The client sends a request to the server with the following information:
There must be a common protocol that both the client and the server speak to communicate with one another. On the Internet that protocol is TCP/IP. The server does most of the work in the relationship: It waits for requests, processes them, and then sends the client the information requested.
Through some client/server applications, like Telnet and the World Wide Web, remote users can actually run applications on the server machine and manipulate data. For instance, remember the salespeople who were tracking sales through individual computers? Well, now they can log onto a central computer using a Telnet application and enter their individual sales figures. The sales data now can be processed together at a central location. Or, using a secure protocol and a more advanced technology, such as a Web server gateway, a user can enter the information on his or her own machine, where it is compiled and sent to the server. The connection time, therefore, only lasts as long as the transmission.
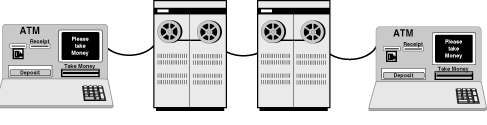
Depending on the needs of a business or organization, there usually is one server or a group of servers. For example, a bank would have a group of servers, one servicing each branch. The server's function is to process information requests. When a request is received by the server, that server performs one of two functions: It either answers the request and updates information or it sends the request to the right place. For example, if information is affected by the request, such as in the case of an ATM transaction, a request for a withdrawal means the account must be debited. In the case of redirecting the request, if someone is using an ATM from a bank with which he or she doesn't have an account, the server for that ATM sends the information request to the server at the customer's bank. In this case, the ATM server is actually acting as a client and the customer's bank is the server. When the information is returned to the ATM, it is "serving" the information back to the client (see Figure 4.6).
Figure 4.6: ATMs are connected to a network of servers that have your banking information.
The applications for this kind of relationship in the business
environment are virtually limitless. Any common source of information,
from price lists and inventory to contact databases and financial
data. Any data that must be accessed and modified by multiple
users can be done very efficiently in this client/server model.
| To understand the client/server relationship, consider something that most of us, for better or worse, have become accustomed to: using the ATM.
Think of the ATM as the client. You utilize the ATM for various banking needs by entering your specific information request. Assume you need cash. You insert your card, from which your account number is read. When prompted, you enter your PIN (personal identification number), how much money you want, and which account to access. The ATM then sends the request to a central server machine. The server machine processes the request, matches your PIN to your account, debits your balance, and sends the reply back to the client, the remote ATM site. The client then acknowledges the result of the request by sending cash and a receipt (you hope). Because all the clients share a common server, your account is always updated. |
If you're going to serve information, you need a computer on which to serve it. Server hardware traditionally has been a minicomputer such as a Sun or a Cray, or a high-end IBM or DEC computer. With the new Pentium and power-PC processor, however, more PCs are being used as servers for limited uses such as a Web or a mail server, or even an FTP file server. For Telnet or database applications, however, more powerful servers are needed. For example, if a company wanted to post employee manuals, memos, and directories on a Web server, or simply serve mail to a medium-sized LAN, a Pentium computer would more than suffice. On the other hand, if a large corporation wanted to maintain an up-to-the-minute nationwide inventory supply, a more powerful computer likely would be required.
You can have multiple software servers on one computer. In a typical intranet, an organization will want a mail server to process and deliver e-mail, an FTP server to manage file transfers, a Web server to host and serve World Wide Web documents, and possibly a database server to store and process data. Each server, or daemon, listens for a specific request. The appropriate server then answers the request. Some servers, like FTPs, file servers, and mail servers, only require a little memory. Others, such as some Web and database servers, need much more RAM to operate. A typical Pentium Web server should operate just fine with 32MB of RAM, whereas a machine running multiple servers might need as much as 128MB RAM, depending on how many concurrent users there are or how many requests must be processed at one time.
To understand how clients work, think about the ATM analogy. The client, the ATM, asks questions to determine the form of the query (deposit, transfer, and so on). It then arranges those questions into a query the server will understand. Next the client sends the query to the server using the correct protocol. Anyone who has programmed computers knows that computers do not respond to plain English-or Spanish for that matter. Commands must be given to the computer in a specific way. The client works along the same model. The client software knows the language spoken by the server and formats the request in a way that the server will understand.
A mail client does much the same. There is a standard mail protocol over the Internet, but dozens of clients take the information. Though your message may be entered in several ways, each client will put it in the correct format to transmit it over the Internet. So, regardless of which mail client you use, your message is sent over the Internet in the same way as all other Internet messages.
Examples of clients are Eudora for mail, Fetch or CuteFTP for file transfer, and Netscape or Internet Explorer for browsing the World Wide Web. The rich variety of clients and servers is why this technology is so important and useful; it doesn't matter what kind of computer you have or which operating system you run-as long as you can speak the basic Internet protocol, TCP/IP, you can connect to the server.
Client hardware can range from an old Apple II computer to a Cray supercomputer. All the client needs is a connection to the server and the capability to run client software. Some new clients, like two-way pagers, Apple Newtons, and other personal data assistants, are clients as well. Although they can't perform many functions, they can send and receive information to and from a server.
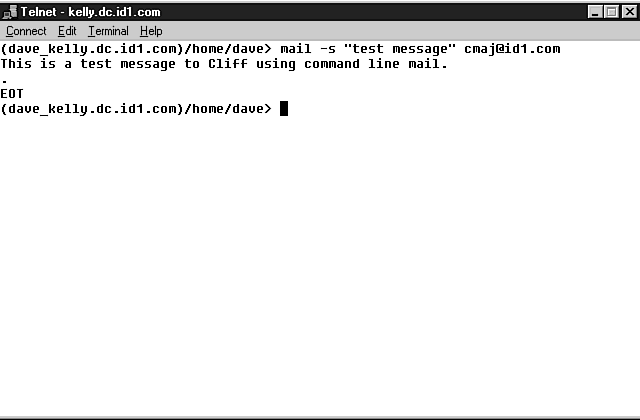
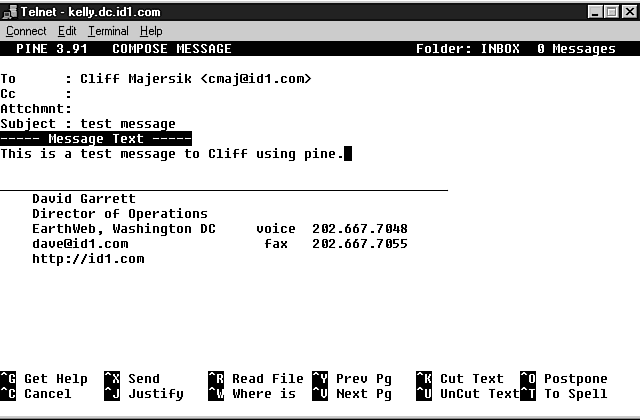
Most client software is available for many computers and operating systems. Client software once was all command-line software, which means it didn't do much except make the connection to the server. It looked much like a DOS prompt. The user had to know specifically what information to feed the server and in what format that information must be in to communicate with the server. Now there are graphical interfaces for most client software. Essentially graphical interfaces perform the same functions as command line software did but are user-friendly. Users make queries by pointing and clicking, and dragging and dropping, while the graphical interface transforms those queries into a language that the server can understand. It then sends the query using TCP/IP. The graphical interface just makes it easier to construct the command if the user doesn't know the arcane protocols and procedures. Figures 4.7, 4.8, and 4.9 show three ways to send mail.
Figure 4.7: Command line is run through the server.
Figure 4.8: Pine is a client program run on a server machine.
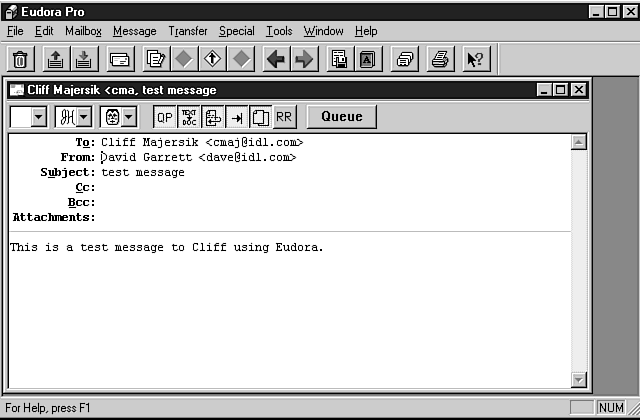
Figure 4.9: Eudora is a client program run on a client machine.
With the advent of the network terminal-a $500 PC receiving much attention among the online world and highly touted by such industry giants as Oracle and AT&T-and other similar devices, client software is likely to function as part of the operating system rather than as individual software. Netscape, the most popular World Wide Web browser, is already doing this by combining into one application mail, FTP, even Internet phone, and soon many other clients. With advancing wireless technology, it is possible that someday day soon you will send and receive e-mail and travel the information superhighway from your cellular telephone (hopefully not at the same time you are navigating the actual eight-lane highway!)
Middleware is the practice of writing programs that use the computer processing capacity of both the server and the client. Right now, client hardware is not being completely utilized because of the current limitations in bandwidth. A mid-level computer, even with a very fast connection, can process data much faster than it can receive it. The goal for the next generation of client/server software is to create a program that will take information from the server, send that information to the client, let the client manipulate it, and then send the results back to the server. For example, in the case of online banking, you could download a bank data form that retrieves your personal credit and financial information from the server along with it. You then could use that application for many banking needs, including transferring funds, applying for a loan, or requesting traveler's checks. The application then would send the information back to the server, complete with all your financial data. Thus, part of the processing is done with the client, and part is done with the server.
The idea of middleware is to provide a cross-platform means of
creating and distributing a software application, regardless of
what kind of computer and operating system is being used by the
client. In this way, an organization can create a specialized,
customized piece of software built to perform specific functions.
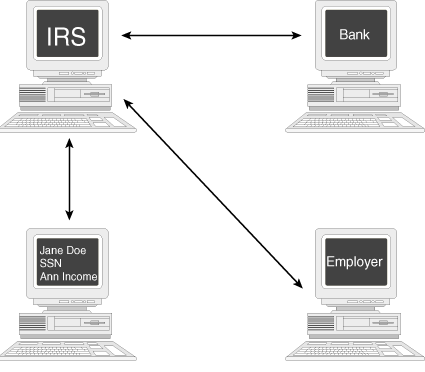
| Benjamin Franklin said that in this world, nothing is certain but death and taxes. Using middleware can ease one of these certainties by simplifying IRS tax procedures. Imagine that the IRS could combine all the past year's tax information as it relates to you. The software application would include all the information on your estimated payments and withheld taxes, as well as information from past tax years and current 1099s. The application also would include any updates or changes in the tax laws. Then, an individual could download the application, answer tax questions directly and manipulate the data, and send the completed information back to the IRS. This process could eliminate the process of organizing information from several sources (employers, banks, and so on). The application could even interface with your own bookkeeping software to make the job that much easier, as shown in Figure 4.10. |
Client/server applications currently dominate the Internet and form the basis for the best tools currently available with which to build intranets. Client/server applications also provide the most flexible platform to build future applications, whatever form they might take. A basic understanding of client/server technology and applications is fundamental in understanding the concepts and functions outlined here. As you will continue to learn throughout this book, all functions you build into your intranet will be based in some way on client/server theory.